
Retrieval-augmented generation (RAG) is a technique that enables large language models (LLMs) to retrieve and incorporate new information from external data sources. This article provides a comprehensive overview of RAG in the context of artificial intelligence, focusing on its mechanisms, benefits, and practical applications. The scope covers the fundamentals of RAG, its system architecture, optimization strategies, and its growing importance in enterprise AI. The content is tailored for AI practitioners, researchers, and general readers interested in AI advancements. Understanding RAG is crucial because it addresses the inherent limitations of LLMs—such as outdated knowledge and hallucinations—by enabling real-time access to up-to-date, domain-specific information.
Introduction to Generative AI and RAG
Retrieval Augmented Generation (RAG) is a powerful technique within the field of generative AI that enables large language models (LLMs) to retrieve and incorporate new information from external data sources. Generative AI models are designed to create human-like text based on the input they receive. These models, including LLMs, are trained on vast but finite datasets sourced from public domains such as books, articles, and websites. However, this training data is static and has a cutoff date, which limits the model's knowledge to information available only up to that point. This limitation can lead to outdated or inaccurate responses when the model encounters queries about recent events or specialized topics.
Retrieval-augmented generation (RAG) addresses these challenges by connecting LLMs with external knowledge bases and data sources. By integrating retrieval mechanisms, RAG enables language models to access relevant documents, databases, and web pages in real-time, enhancing the accuracy and relevance of their responses. This approach is especially valuable for knowledge-intensive tasks, such as question answering, research, and customer support, where up-to-date and domain-specific information is crucial.
Generative AI applications span a wide range of use cases, including chatbots, language translation, text summarization, and content generation. RAG enhances these applications by grounding generative AI outputs in factual, external data, thereby reducing hallucinations and improving user trust. Moreover, RAG allows organizations to leverage their internal data without the computational and financial costs associated with retraining or fine-tuning foundation models.
What is Retrieval Augmented Generation (RAG)?
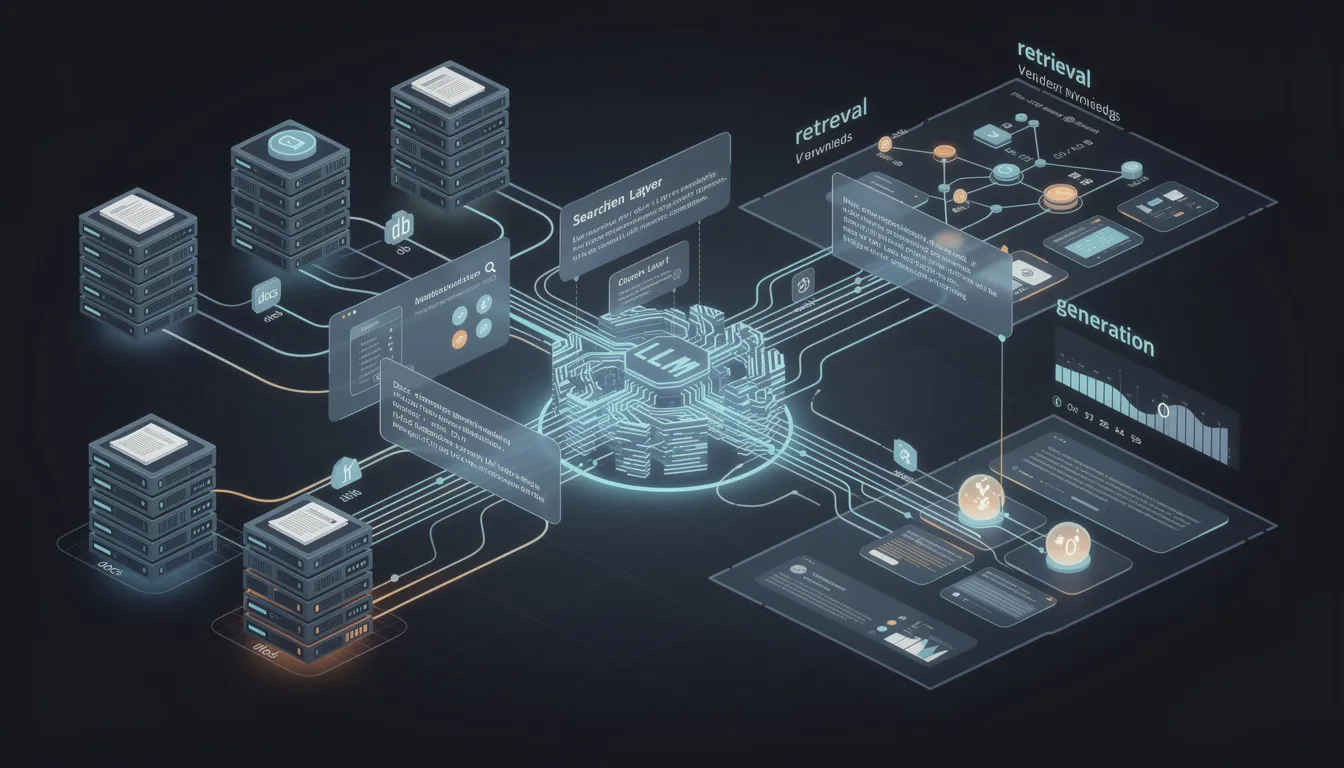
Retrieval-augmented generation (RAG) is a technique that enables large language models (LLMs) to retrieve and incorporate new information from external data sources. RAG systems combine the strengths of information retrieval and generative AI, allowing models to dynamically access and utilize up-to-date knowledge during the response generation process. This makes RAG particularly effective for tasks that require current, accurate, and contextually relevant information.
How Retrieval Augmented Generation Works
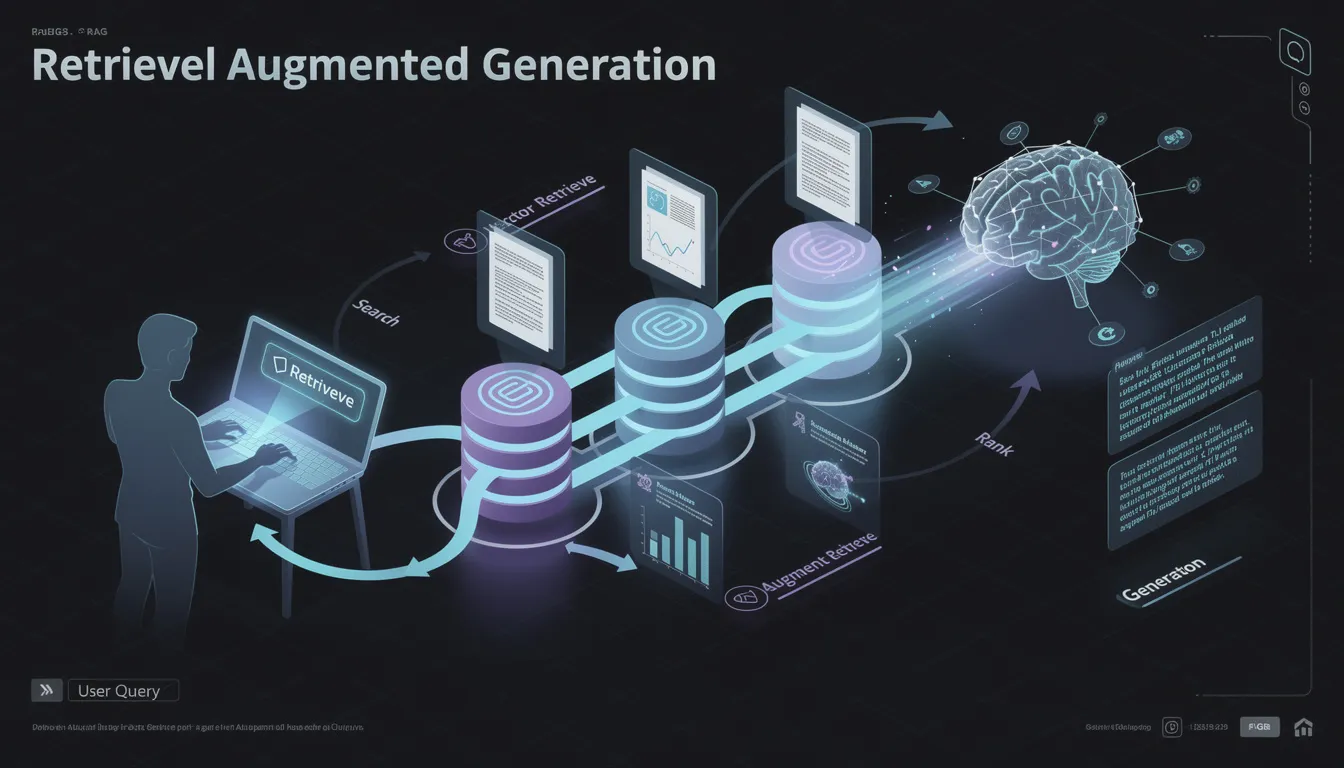
Retrieval Augmented Generation operates through a series of coordinated steps that blend information retrieval with text generation to produce more accurate and context-aware outputs. The process can be broken down into several key stages:
User Query Processing
The process begins when a user submits a query or input to the system. The system first processes this input to understand the user's intent and information needs.
Embedding and Vector Search
The input is then converted by the retrieval model into numerical representations known as embeddings. These embeddings enable the system to perform a vector search against vector databases that store embeddings of external data sources.
Hybrid Search Techniques
The retrieval model identifies and ranks relevant documents or data chunks from multiple data sources, such as internal documents, web pages, or specialized data repositories. This retrieval often employs hybrid search techniques, combining semantic search with keyword search to optimize the relevance and accuracy of search results.
Prompt Augmentation
The retrieved chunks are integrated with the original input prompt to create an augmented prompt. This augmented prompt provides the generative model with both the user's question and the relevant context.
Response Generation
The generative AI model uses this augmented context to generate responses that are grounded in the retrieved information, rather than relying solely on its static training data. This tight integration of retrieval and generation reduces the risk of inaccurate responses and enhances the overall response quality. Additionally, by incorporating external knowledge sources dynamically, RAG systems minimize the need for frequent model retraining, thereby saving computational and financial costs.
Components of a RAG System
A typical RAG system consists of several key components working in harmony to deliver accurate and context-aware answers:
-
Retrieval Model: Handles the information retrieval process by querying the knowledge base using the user's input. It employs embedding models to convert text data into numerical representations and performs vector search within vector databases to find the most relevant documents or data chunks.
-
Knowledge Base: A curated repository of external data, which can include structured data, unstructured documents, internal data, and web pages. This repository is continually updated to ensure that the RAG system accesses the most current and relevant information.
-
Integration Layer: Serves as the system's coordination hub, combining the retrieved relevant data with the original user input to form the augmented prompt. It orchestrates the flow of information between the retrieval model and the generative model, ensuring seamless communication and context augmentation.
-
Generative Model: Uses the augmented prompt to synthesize a response that incorporates both its pre-existing knowledge and the newly retrieved external information. Techniques such as fine-tuning and prompt engineering can be applied to optimize the model’s response quality and relevance.
These components enable RAG architectures to support complex use cases, such as answering user questions with precise, domain-specific knowledge, performing natural language processing tasks, and handling knowledge-intensive queries that require access to multiple sources of data.
Reference Architecture for RAG Systems
The workflow of a RAG system typically follows these steps:
-
Document Preparation and Chunking: Large documents are divided into manageable segments or chunks for embedding and retrieval.
-
Vector Indexing: Each chunk is transformed into a numerical embedding and stored in a vector database for efficient similarity search.
-
Retrieval: When a user submits a query, the system retrieves the most relevant chunks from the vector database using semantic and/or keyword-based search.
-
Prompt Augmentation: The retrieved chunks are combined with the user’s original query to form an augmented prompt, which is then passed to the generative model for response generation.
This stepwise process ensures that the generative model has access to the most relevant and up-to-date information when generating responses.
Fine Tuning and Optimization
Although RAG significantly enhances response accuracy by integrating external data, fine-tuning and optimization remain important for maximizing system performance.
Fine-Tuning
Fine-tuning involves adjusting the generative model’s parameters, architecture, or training data to better align with specific tasks or domains. This process can improve the model's ability to generate accurate answers and handle specialized language or terminology.
Optimization Techniques
Optimization techniques, such as supervised learning, reinforcement learning, and evolutionary algorithms, help refine the model's outputs based on metrics like accuracy, precision, recall, and coherence. These techniques can also reduce errors and inconsistencies in the model’s response.
Chunking Strategies
To maintain high-quality results, RAG systems employ chunking strategies to divide large documents into manageable segments for embedding and retrieval. This ensures that the augmented prompt remains within the model’s context window and that the retrieved chunks are semantically coherent and relevant to the user’s question.
By combining retrieval augmented generation with fine-tuning and optimization, organizations can build robust AI applications that deliver accurate, up-to-date, and contextually relevant responses across a wide range of domains and use cases.
Retrieval-Augmented Optimization

Retrieval-augmented optimization is a critical aspect of enhancing the performance and response quality of Retrieval-Augmented Generation (RAG) systems. While RAG integrates external data to improve the relevance and accuracy of generated content, optimization techniques focus on refining how the system processes, retrieves, and utilizes this information to deliver the best possible outcomes.
Importance of Optimization in RAG
Optimization ensures that the retrieval and generation components work harmoniously, minimizing errors such as hallucinations, irrelevant responses, or contradictions. It also improves the efficiency of the system by reducing computational and financial costs associated with processing large volumes of data and generating responses.
Key Optimization Techniques
-
Fine-Tuning the Generative Model: Adjusting the parameters and training of the language model to better handle domain-specific language, terminology, and response styles. Fine-tuning helps the model generate answers that are more accurate and aligned with user expectations.
-
Prompt Engineering: Designing and refining the augmented prompts that combine user queries with retrieved data. Effective prompt engineering guides the generative AI to focus on the most relevant information, improving the coherence and factual grounding of responses.
-
Chunking Strategies: Dividing documents into appropriately sized chunks for embedding and retrieval. Proper chunking balances the need for semantic coherence with the limitations of the model’s context window, ensuring that retrieved information is relevant and manageable.
-
Relevance Scoring and Re-Ranking: Implementing algorithms to assess and prioritize retrieved documents or data chunks based on their relevance to the user query. Re-ranking helps surface the most pertinent information, which in turn enhances the quality of the generated response.
-
Hybrid Search Methods: Combining semantic vector search with traditional keyword search to improve retrieval accuracy. Hybrid search leverages the strengths of both approaches, ensuring that relevant results are not missed due to vocabulary mismatches or semantic nuances.
-
Continuous Knowledge Base Updates: Regularly refreshing the external data sources and their embeddings to maintain the system’s access to current and accurate information. This process prevents degradation in response quality over time.
-
Evaluation Metrics and Feedback Loops: Using metrics such as accuracy, coherence, groundedness, and user satisfaction to measure system performance. Feedback loops enable iterative improvements by incorporating human evaluations and automated assessments.
Benefits of Retrieval-Augmented Optimization
By applying these optimization strategies, organizations can achieve:
-
More Accurate Responses: Enhanced alignment between retrieved data and generated answers reduces misinformation and hallucinations.
-
Improved Response Quality: Coherent, context-aware, and relevant outputs that better satisfy user queries.
-
Cost Efficiency: Optimized retrieval and generation reduce unnecessary computation, lowering operational expenses.
-
Scalability: Efficient handling of larger and more complex data sources supports broader use cases and higher user loads.
-
Adaptability: Easier incorporation of new data and evolving domain knowledge without extensive retraining.
In summary, retrieval-augmented optimization is essential for maximizing the effectiveness of RAG systems. It bridges the gap between raw data retrieval and high-quality generative AI outputs, enabling organizations to deploy AI solutions that are both powerful and reliable.
Conclusion and Future Outlook
Retrieval Augmented Generation (RAG) is rapidly evolving into a foundational component of enterprise AI architecture. Its role is shifting beyond merely filling gaps in knowledge to creating structured, modular, and intelligent systems that seamlessly integrate with large language models (LLMs). Hybrid architectures are emerging that combine RAG with structured databases and function-calling agents, enabling more sophisticated and reliable AI applications. As LLM architectures mature, RAG systems are expected to become more seamless and contextual, capable of handling real-time data flows and multi-document reasoning. This evolution positions RAG as a standard approach for integrating dynamic data into AI applications without the need for extensive retraining, making it indispensable for organizations seeking accurate, up-to-date, and domain-specific AI solutions.
Frequently Asked Questions (FAQs) about Retrieval-Augmented Generation (RAG)
What is Retrieval Augmented Generation (RAG)?
Retrieval-augmented generation (RAG) is a technique that enables large language models (LLMs) to retrieve and incorporate new information from external data sources. This allows models to produce more accurate, context-aware, and up-to-date responses.
How does RAG improve AI model responses?
By combining information retrieval with generative AI, RAG grounds model outputs in factual external knowledge, reducing hallucinations and improving response quality. It typically involves four steps: document preparation and chunking, vector indexing, retrieval, and prompt augmentation.
What types of data can RAG access?
RAG systems can utilize various data sources, including internal documents, databases, web pages, and specialized datasets. This data is often transformed into numerical representations stored in vector databases for efficient retrieval.
Does RAG eliminate the need for retraining AI models?
While RAG significantly reduces the need for frequent retraining by dynamically incorporating new data, it does not completely eliminate the need for model fine-tuning or updates in some cases.
How does RAG enhance user trust?
RAG systems can include citations to the knowledge sources used in generating responses, allowing users to verify information and increasing transparency and trustworthiness.
Partner with Sterling Media & Communications
At Sterling Media & Communications, we understand the transformative power of RAG and generative AI technologies. Whether you are looking to implement cutting-edge AI solutions or optimize your existing systems, our expert team is here to help you navigate the complexities of RAG implementation and maximize your AI investment. Visit us at smcww.co.uk to learn more about how we can support your journey toward smarter, more accurate, and trustworthy AI applications.
Let Sterling Media & Communications be your trusted partner in harnessing the future of AI with Retrieval Augmented Generation.

0 comments